7B开源,能力全面提升!
文章正文
发布时间:2025-05-14 04:10
近日,360自研AI大模型360智脑7B参数升级版(360Zhinao2-7B)正式开源,现已上线Github开源社区可免费商用。该模型是继今年4月 360Zhinao1-7B 开源后的重要更新,模型各项能力得到全面提升,不仅大幅提升了中英文通用能力,还显著增强了模型的数学逻辑推理能力。模型在中文考试CEval、复杂数学推理math、中文阅读理解C3、中文摘要lcsts等评测集上展现超强竞争力,在10B以下开源模型上排名第一。模型在 IFEval、MT-bench、CF-Bench三个评测上具备竞争力,比如在 IFEval (prompt strict) 上,在开源7B尺寸上得分最高。优异的模型效果,主要得益于360Zhinao2-7B在基础模型训练和模型对齐训练两个方面,均取得了重大进展,下面详细介绍下一些技术细节。
一. 基础模型训练
1.1 模型结构与360Zhinao1-7B一样,模型主要是基于Transformer的dense模型结构,最大不同是采用GQA替代MHA,模型推理吞吐效率大幅提升。1.2 预训练数据基础模型效果上优异表现,主要得益于预训练数据质量得到了大幅的提升。在360Zhinao1-7B技术报告中的大量数据工作外,在网页数据处理和数据合成方面,做了大量的工作。网页数据多样性和质量大幅提升在minhash文档去重基础上增加语义向量去重,进一步提升网页数据的信息密度和均衡性。
将网页数据拆分成42类,适当降采占比过高数据,增加数据的多样性。
对网页进行改写,大幅提升网页内容组织形式丰富度,网页质量也有显著提升。
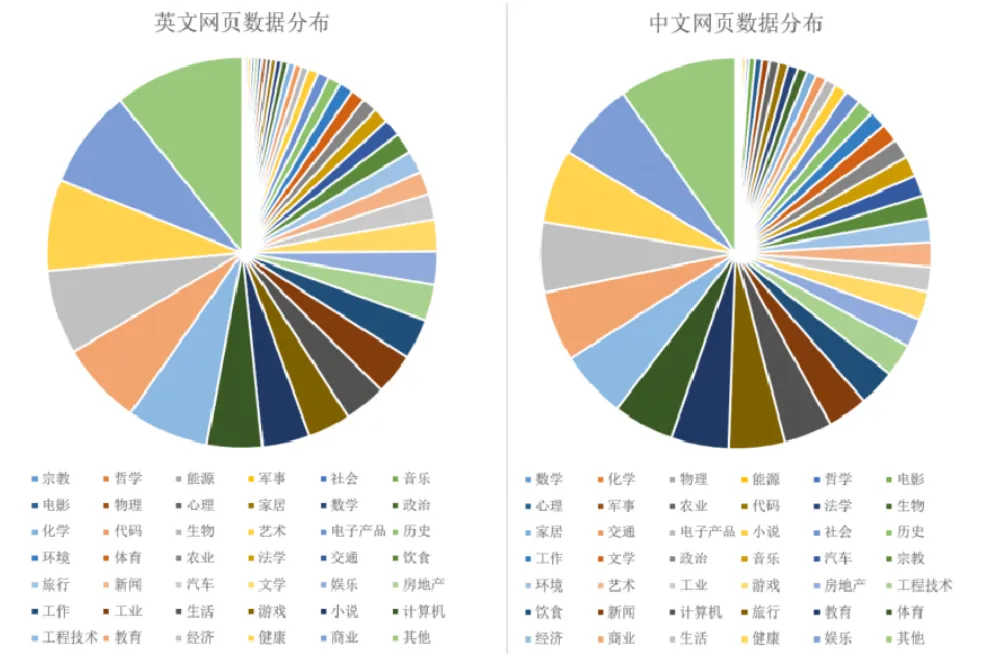
图1:中英文网页真实分布占比情况大规模数据合成弥补真实数据不足
图2:数据合成流程示意图我们加大了数学、代码、指令数据的占比。现实中该类数据比较匮乏或质量不高,如:数学经常是只有题目没有解题过程及答案;代码数据只有代码而缺乏代码功能说明文字;开源的指令数据量少且难度不足。为了解决这些问题,我们在合成数据上做了大量的工作:合成数据多样性:为了解决合成数据重复性的问题,我们借助了真实分布的数据作为合成的上下文,或者利用真实数据生成主题和子主题,极大的提升了合成数据的多样性。
合成数据难度:为了解决合成数据过于简单的问题,我们采用迭代合成的方法,逐渐加大合成数据的难度。
合成数据质量:为了提升合成数据的质量,我们使用大模型对数据进行多维度打分,过滤掉低质量的数据。
调整数据配比,增加数学、代码和指令数据占比相比360Zhinao1-7B,我们大幅降低了网页数据的占比,增加了数学、代码、指令三种类型的数据占比,模型的推理能力和指令遵循能力有了显著的提升。
图3:预训练数据配比
1.3 预训练方法不同于360Zhinao1的一阶段训练方式,我们采用当前主流的两阶段训练方法。第一阶段总共训练10T token,采用cosine学习率,最大学习率3e-4,为了确保退火阶段LR具有较大斜率,我们适当加大了第一阶段的最小学习率;第二阶段退火训练,我们加大了高质量数据的占比,训练了100B高质量token,学习率LR直接decay到0。360Zhinao2-7B总共训练数据量达10.1T token。1.4 基础模型效果我们使用了开源工具OpenCompass对模型进行评估,对比了近半年国内外开源的10B以下模型,360Zhinao2-7B具备较强的竞争力。360Zhinao2-7B在CEval(中文考试)、C3(中文阅读理解)、lcsts(中文短文本摘要)等中文benchmark上表现不俗,中文benchmark均分排名第一。在挑战性的竞赛数学数据集math上,同样排名第一。360Zhinao2-7B模型在中文处理能力、复杂数学推理能力两个方面,具备优势。
表1:基础模型benchmark效果
二. 模型对齐训练
采用iterative DPO,off-policy DPO以及PPO三种进化方式分别对齐,再采用先内插再外插的方法,极致提升模型的天花板。结合高质量人工标注的微调数据以及可验证的复杂指令遵循数据,大幅增强了模型在实际应用场景中的指令遵循能力。2.1 后训练数据360自有通用微调数据50w,该数据综合考虑技能多样性及360垂直业务数据,生成方法如下:数据多样性:据360自有标签体系进行领域,意图,难度,长度的分层采样,确保指令多样性
数据质量:用开源数据以及自有的偏序数据训练了360zhinao-pro-rm(reward bench得分92.59),使用该模型进行样本筛选,过滤低质数据。reward model对sft数据打分在类别统计上样本得分符合正态分布,删除规则采用:去除样本分数小于本类别均值和标准差之差的数据。
复杂指令进化:用进化方式做复杂指令优化,优化指令跟随能力。指令进化过程中采用self-instruction、wizard和基于CFbench多类型约束的auto-evol方法。
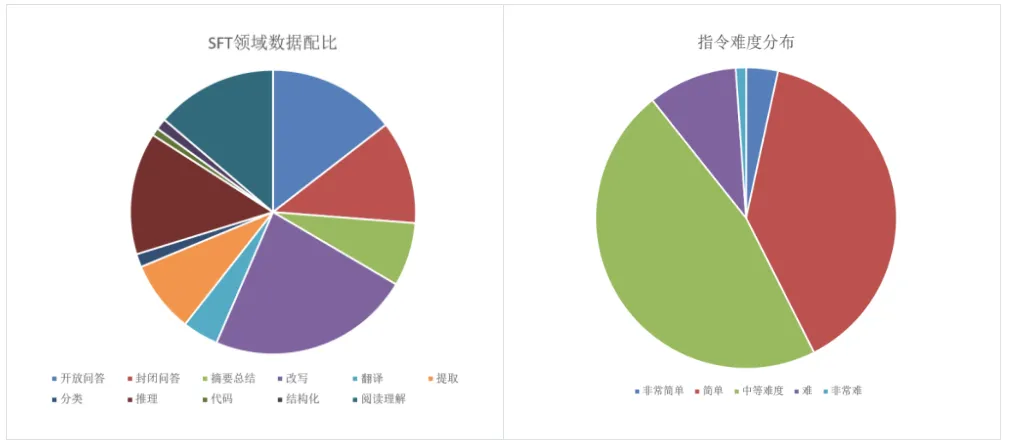
图4:后训练数据分布情况2.2 训练方法1、全参数微调:基于50w通用后训练数据,进行全参数微调。微调中使用packing方式(packing训练速度快、且因与pre-train形式保持一致,性能不弱于不packing方案),最大packing长度选择8192,lr、batch_size、weight decay分别设置为:1e-5、 128、 0.1,epoch数为6。综合考虑榜单和自有评测集合得分,选最优checkpoint作为sft-base。2、PPO:在近两年的时间中,我们增量地收集了百万级pair偏好数据,训练了360zhinao-pro-rm(reward bench得分92.59),基于该RM做PPO训练,具体算法使用ReMax或GRPO。3、Iterative on-policy DPO:使用sft-base模型在训练prompt上采样多个答案,用360zhinao-pro-rm打分,取最高最低分组pair进行DPO训练。我们迭代地使用这种on-policy 全参DPO提升模型效果。4、LoRA off-policy DPO:基于人类标注好的偏好对,中英文各1万条,采用QLoRA技术实现高效训练。训练参数一般设置为:LoRA rank为256,LoRA alpha为512,LoRA dropout为0.05,最大序列长度为2048。训练完成后,将多个LoRA adapter合并至原始模型。5、模型合并:在内部评测集合v4.0上,针对上述若干个模型做自动评测,发现不同模型各有其优势技能,考虑模型合并方案。基于sft模型为base,融合PPO和DPO后的模型做内插得到模型v1,然后仍以sft模型为base和v1模型进行外插,外插系数0.2 最终得到360Zhinao2-7B-Chat-4k。
图5:后训练全流程图。我们在SFT后进行了PPO和DPO,并将优势技能不同的模型合并和插值。
2.3 模型效果我们在IFEval、MT-bench、CF-Bench三个流行的评测上对360Zhinao2-7B-4K模型进行了评测比较,模型具备竞争力。在IFEval (prompt strict) 仅次于glm4-9b,在7B尺寸上得分最高:
表2:
微调模型benchmark效果2.4 长文本微调
图6:长文本微调流程图与360Zhinao1开源时的做法基本一致,我们将RoPE base依次扩大为1,000,000和50,000,000,混合长短文本的SFT数据依次拼接至32k和360k,将gradient checkpointing、ZeRO3 offload和序列并行等技术结合,依次微调得到32k和360k长文本模型。在各个32k benchmark上位列第一梯队。
表3:
长文本benchmark效果
